")
مطالب منتخب
-
 جایزه دکتر روستاآزاد
جایزه دکتر روستاآزاد
با حضور رئیس مجلس از جایزه دکتر روستاآزاد رونمایی شد
-
 ویژهنامه
ویژهنامه
ویژهنامه پاسداشت دکتر رضا روستاآزاد
-
 سالنامه 1403
سالنامه 1403
مروری جامع بر عملکرد اندیشکده حکمرانی شریف در سال 1402
-
 خبرنامه/شماره 22
خبرنامه/شماره 22
آخرین نشستها و مقالات پژوهشگران اندیشکده حکمرانی شریف
-
 کتاب
کتاب
«دولت سیزدهم در گام اول» شامل نقد و بررسی عملکرد دولت در حوزه اقتصادی، سیاست خارجی، فرهنگ و رسانه و علم و فناوری
-
 گزارش سیاستی
گزارش سیاستی
نظر اندیشکده حکمرانی شریف بر سند تنظیمگری پلتفرم های یونسکو
-
 مراسم یادبود
مراسم یادبود
بزرگداشت مرحوم دکتر رضا روستاآزاد
اقتصاد رفتاری, اقتصاد سیاسی, برنامههای انجام شده, حوزه های تخصصی, دیدگاه تخصصی, محصولات, مطالعات موردی سیاستهای تغییر رفتار
[*] ارزیابی تأثیر شامل اندازهگیری کمّی میزان تغییری است که در یک شاخص نتیجهای، بر اثر اجرای سیاست ایجاد شده است. لذا از این تعریف معلوم میشود که اولاً ارزیابی تأثیر به شدت به منابع آماری وابسته است و در صورت محدودیت در دادهها، با مشکل جدی روبرو خواهد شد. ثانیاً اینکه جدا کردن تأثیر حاصل از اجرای سیاست از سایر تأثیرات ممکن، مهم است؛ یعنی پاسخ به این سؤال که «اگر سیاست اجرا نمیشد، چه اتفاقی میافتاد و اجرای سیاست چه تأثیری بر آن داشته است؟»، برای ما از دانستن تغییرات مطلق شاخصهای نتیجهای، مهمتر است. به همین خاطر در این ارزیابیها معمولاً از یک گروه مقایسه استفاده میشود؛ مگر موارد معدودی که کاملاً واضح است که تغییرات، ناشی از مداخله است و رابطه علّی مداخله با نتایج، کوتاه و مستقیم و سایر تغییرات محیطی بسیار محدود و قابل کنترل است.

برای توضیح بیشتر، فرض کنید که بخواهیم صرفاً از مدلسازی رگرسیونی برای ارزیابی تأثیر مداخله استفاده کنیم؛ در این صورت، همزمانی[۱] میان متغیرهای مداخله با شاخصهای نتیجه را خواهیم یافت. اما هر چقدر هم که میزان این همزمانی قابل توجه باشد، به تنهایی چیزی راجع به رابطه «علیت» به ما نمیگوید. اگر بخواهیم نتیجهگیری کنیم که این مداخله ما بوده که منجر به تغییر شده، باید به تأثیرات محیط نیز توجه کنیم. این کار در صورتی ممکن است، که از یک الگوی تخصیص تصادفی استفاده کنیم که در این حالت، اصطلاحاً با یک آزمایش[۲] روبرو هستیم. با این کار، جامعه را بهطور تصادفی به دو زیرجامعه تقسیم میکنیم: یک گروه را تحت مداخله مورد نظر قرار میدهیم (گروه treatment) و دیگری را بدون دستکاری رها میکنیم (گروه comparison). پس از انجام مداخله، وضعیت این دو گروه را مقایسه میکنیم تا نتیجه مداخله را ارزیابی کنیم.
لذا برای داشتن یک آزمایش ایدهآل، اینکه افرادی تحت مداخله قرار گرفتهاند و یا نگرفتهاند، کاملاً تصادفی بوده است. در این صورت مطمئن میشویم که تغییرات صرفاً به خاطر مداخله بوده و نه سایر عوامل و خصوصیات آنها و در این صورت دو گروه را همسان (equivalent) مینامیم. اما معمولاً در سیاستها، انتخاب افرادی که مورد مداخله قرار میگیرند بر اساس خصوصیاتی انجام میگیرد (همانطور که از یادداشتهای قبلی به خاطر دارید، افرادی درون جامعه و یا بخشهای هدف قرار میگیرند که دارای خصوصیات مشخصی باشند) و در نتیجه انتخاب افراد مورد مداخله، عمداً تصادفی نیست. لذا در عمل، موارد استفاده آزمایش بسیار محدود است؛ مثلاً سیاستهای کاهش جرم، بیشتر در مناطقی انجام میگیرد که نرخ جرایم در آنها بالاتر است. یا خودبهخود افرادی در برنامههای آموزش اشتغال ثبتنام میکنند که مهارتهای پایینی دارند. یا افرادی در برنامههای ترک سیگار شرکت میکنند که انگیزه بیشتری برای بهبود وضعیت زندگی خود دارند. همچنین نمیتوان قانون مقابله با رانندگی افراد مست را صرفاً برای یک گروه آزمایشی از آدمها اعمال نمود!
البته در مواردی، میتوان خودِ سیاست را طوری تدوین نمود که انتخاب تصادفی گروه مقایسه ممکن شود. بهعنوان مثال به نمونه موردی زیر توجه کنید:
نمونهای از یک آزمایش کنترلشده تصادفی (RCT) [۵]
شواهد قابل توجه و زیادی در خصوص اثربخشی برنامههای کنترل و کاهش رفتارهای آسیبزا در سراسر دنیا وجود دارد. شواهد تحقیقات در انگلیس نیز در خصوص این برنامهها فراوان است. در پروژهای که در این زمینه انجام شد اثربخشی برنامهای تحت عنوان مهارتهای تفکر مترقّی[۳] (ETS) در انگلستان مورد بررسی قرار گرفت.
هدف اصلی پروژه اندازهگیری تأثیر دورههای ETS بر «تکانهای بودن»[۴] در افراد مجرم بزرگسال (بالای ۱۸ سال) و تحقیق درباره اینکه چه تغییراتی در سطح تکانهای بودن با تغییر در رفتار زندانیها، ایجاد میشود، بود. تکانهای بودن به عنوان رفتاری هدفگذاری شد که انتظار میرفت در طی این دورههای ETS تغییر یابد و این رفتار به عنوان شاخص نتیجهای این برنامه در نظر گرفته شد. انتخاب این رفتار به عنوان شاخص نتیجهای هم بر اساس تحقیقاتی بود که در این زمینه انجام شد و نتایج آنها وجود ارتباط بین تکانهای بودن و ارتکاب جرم را نشان میداد.
آزمایش کنترلشده تصادفی به منظور کاهش انحرافات در تخصیص افراد به گروههای تحت مداخله و مقایسه، در این برنامه اجرا شد. البته این نوع آزمایشها به ندرت در زندانهای انگلستان اجرا شده بود و علت آن هم نگرانیهای اخلاقی درباره جداکردن دو گروه آزمایش بود. این نگرانیها با ایجاد یک لیست انتظار از افرادی که تحت آزمایش نبودند برطرف شد به گونهای که نهایتاً همه مجرمان تحت مداخله قرار میگرفتند. این روش البته نوع خاصی از اجرای آزمایشهای کنترل شده تصادفی است. در هر صورت ارزیابی تأثیر دورههای ETS بر ارتکاب مجدد جرم از طریق این مطالعه ممکن نبود و علت هم روشی بود که برای رفع نگرانی از اجرای ناعادلانه این برنامه در زندانها اتخاذ شد. در عین حال این مطالعه در نهایت با توجه به تأثیرات کوتاهمدت برنامه ETS بر مجرمان، نتایج مثبتی را نشان میداد. خصوصاً اینکه همه گزارشهای بعد از آن، حاکی از کاهش رفتارهای تکانهای و ضدامنیتی در زندانها بود.
از نمونه فوق معلوم میشود که همانطور که قبلاً نیز اشاره شد، باید از همان ابتدای تدوین سیاست، به دلالتهای ارزیابی توجه داشت. باید گروههای مقایسه از ابتدا شناسایی شده و دادههای اولیه مربوط به آنها گردآوری شود. همچنین میتوان با اعمال برخی تعدیلات در سیاست، ایجاد گروه مقایسه را ممکن نمود:
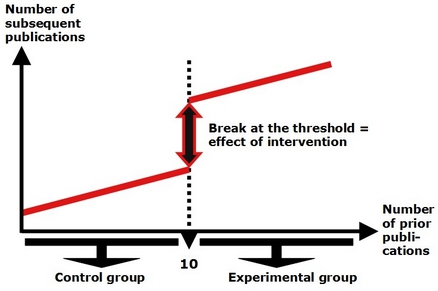
گاهی اوقات میتوان گروه مقایسه تشکیل داد، ولی مطمئن هستیم که دو گروه، همسان نخواهند بود و در نتیجه با یک آزمایش کامل روبرو نخواهیم بود. مثلاً فرض کنید یک گروه به خاطر داشتن خصوصیات خاصی انتخاب شوند (که عمدتاً در سیاستها، همین موضوع وجود دارد و یک سیاست، همه مردم را یکسان مخاطب قرار نمیدهد) یا اینکه افراد داوطلب تحت مداخله قرار گیرند و سایرین به عنوان گروه مقایسه انتخاب شوند. چیزی که در این موارد مهم است، آن است که حتیالامکان متغیرهایی که موجب انحراف از انتخاب تصادفی بودهاند، شناسایی شوند تا بتوان آنها را در تحلیلها در نظر گرفت (در بحث مربوط به شبهآزمایشها به این موارد خواهیم پرداخت).
تا اینجا فهمیدیم که برای اینکه ببینیم آیا سیاست در جامعه هدف تأثیرگذار بوده یا نه، باید یک گروه مقایسه که در ابتدا با گروه مورد مداخله همسان باشد، داشته باشیم. مداخله، در گروه مقایسه انجام نمیگیرد و در گروه هدف، اجرا میشود. سپس باید تحقیقی طراحی شود که مشخص کند آیا در نهایت، مداخله منجر به تغییر قابل توجهی شده است یا خیر. در ادامه به این میپردازیم که چگونه باید بفهمیم آیا تفاوت معناداری میان گروه مداخله و گروه مقایسه وجود دارد یا نه؟
طراحی یک تحقیق مناسب برای ارزیابی تأثیرفرض کنید پس از انجام مداخله در یک گروه، نتایج هر دو گروه به ما داده شده است و تفاوتهایی میان این دو مجموعه مشاهده شود. علاوه بر تفاوتهایی که ممکن است در نتیجه مداخله ما، در دو جامعه قابل مشاهده باشد، دو عامل دیگر هم ممکن است این تفاوتها را ایجاد کرده باشد:
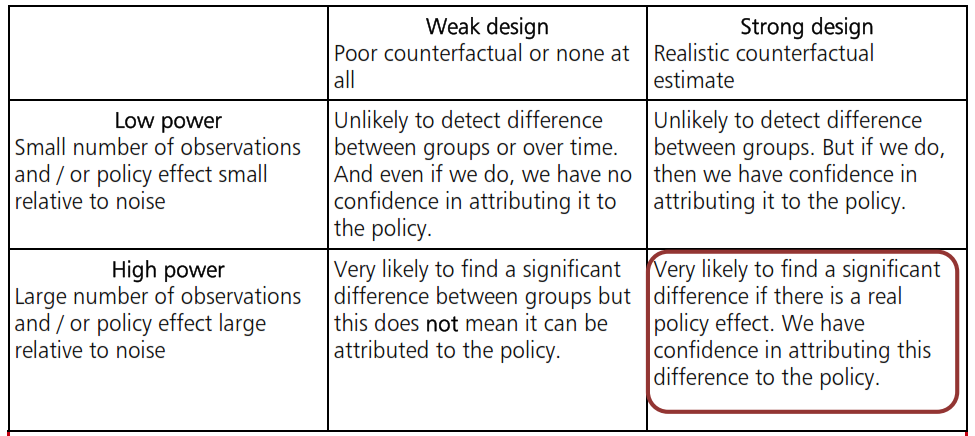
- وجود تفاوتهای ذاتی (فارغ از مداخله ما) در دو گروه؛ اینکه آیا تحقیق میتواند این تفاوتهای سیستماتیک (نه تصادفی) میان دو گروه را درک کند و در نظر بگیرد، «قوت طراحی»[۸] نامیده میشود (که یک کمیت عددی نیست).
- همچنین، همیشه تفاوتهایی میان افراد دو گروه وجود دارد که سیستماتیک نیست و ناشی از واریانسهای طبیعی خودِ دو جامعه است. مثلاً اینکه به طور اتفاقی امروز یک نفر حال خوبی ندارد یا اینکه بهصورت شانسی در یک امتحان موفق شده. تحقیق باید طوری طراحی شده باشد که اثرات سیاست را با وجود این نوسانات طبیعی بفهمد؛ به این خصوصیت تحقیق، «توان طراحی»[۹] گفته میشود که کمیتی عددی است و به این صورت تعریف میشود: «احتمال اینکه اگر اثر واقعی، مقدار مشخصی باشد، تحقیق بتواند آن را در یک سطح اطمینان خاص، کشف کند». توان، به نسبت (Signal-to-noise ratio) و همچنین به تعداد مشاهدات (حجم نمونه) بستگی دارد.
برای درک بهتر تفاوت میان قوت و توان، به جدول زیر نگاه کنید:
مفهوم توان به ما میگوید که هر چه نسبت کمتر باشد، برای یک سطح اطمینان خاص، تعداد نمونه بیشتری لازم است (چون در این صورت، درک کردن اثر واقعی، از میان تلاطمات طبیعی درون جامعه کار مشکلی است). مثلاً فرض کنید میخواهیم با استفاده از آزمون t، تفاوت میان میانگین دو جامعه (جامعه مورد مداخله با جامعه مقایسه) را با ۸۰%=توان در سطح اطمینان ۹۵% تست کنیم (آیا میتوانید معنی این جمله را به لحاظ آماری توضیح دهید؟). برای این کار، تعداد نمونه آماری لازم (مجموع گروه مداخله و مقایسه) در جدول زیر آمده است:
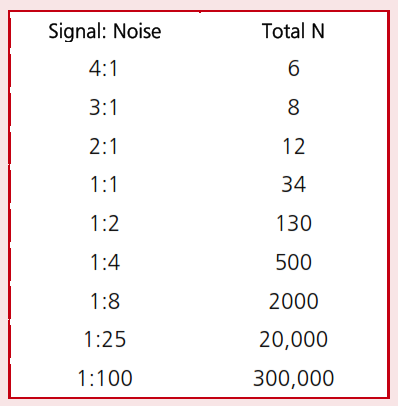
اما چگونه میتوان پیش از مطالعه جامعه، نسبت فوق را تخمین زد و تعداد نمونه را تعیین نمود؟ میزان noise، از دادههای قبلی قابل تخمین زدن است. ولی signal (یا همان میزان اثر مداخله)، از روی مدل منطقی مداخله تخمین زده میشود. علاوه بر آن، میتوان مقدار مطلوب اثر مداخله را بهعنوان Signal درنظر گرفت (درواقع دست بالا را در نظر میگیریم؛ چون اگر اثر، کمتر بوده باشد، در هر حال مداخله ناموفق بوده و برایمان فرقی نمیکند که آیا تحقیق، آن را کشف کند یا خیر!).
نتیجه میگیریم که ارزیابی تأثیر، تنها در مواقعی که تأثیر مورد انتظار، به اندازه کافی بزرگ باشد و از نوسانات طبیعی داخل سیستم قابل تفکیک باشد، مفید است. (این که چقدر باید بزرگ باشد، به نحوه مدلسازی ما بستگی دارد.) در شرایطی که شاخص نتیجه، با نوسانات بسیاری همراه باشد، میتوان به دنبال کشف تغییرات در برخی شاخصهای نتیجهای واسط بود که در مدل منطقی بدست آمده است؛ مثلاً کشف اثر یک کمپین تبلیغاتی در زمینه تغذیه سالم بر نتیجه نهایی سلامت افراد میتواند بسیار مشکل باشد، اما بهوسیله یک پیمایش میتوان برخی تغییر رفتارها (مثلاً مصرف زیاد میوه و سبزیجات) را که کمپین دنبال میکرد، سنجید که حاوی شواهدی است در زمینه میزان موفقیت اطلاعرسانی کمپین.
در شرایط یک آزمایش کامل (که انتخاب تصادفی باشد)، به راحتی میتوان با یک آزمون t (یا یک آزمون ANOVA)، تفاوت میان دو گروه را تست کرد و اگر تفاوت معناداری (significant) وجود داشت، آن را به اثر مداخله نسبت داد.
اکنون به عامل «قوت» طراحی میپردازیم. بیشترین قوت، زمانی رخ میدهد که انتخاب دو گروه آزمایش و کنترل کاملاً تصادفی باشد. در شرایطی که نتوان دو جامعه را بهصورت تصادفی انتخاب کرد و تفاوتهای سیستماتیک، میان آنها وجود داشته باشد (و بنابراین دو گروه، همسان نباشند)، به جای آزمایش، با یک شبهآزمایش (Quasi-experiment) روبرو هستیم. این در شرایطی است که سایر متغیرهایی که غیر از مداخله بر نتایج تأثیر میگذارند، بهصورت یکسان در دو جامعه مورد مداخله و مقایسه وجود نداشته باشند (یا انتخاب تصادفی انجام نگرفته باشد). در این شرایط، برای طراحی یک تحقیق مناسب، میتوان از سه راهحل استفاده کرد:
- رویکرد کنترل: کنترل تفاوتها، با در نظر گرفتن متغیرهای مربوطه در مدلهای رگرسیونی
- رویکرد matching: یافتن زیرمجموعههایی از دو گروه که بیشتر به هم نزدیک باشند (با استفاده از تکنیکهایی چون PSM[۱۰]) و مقایسه آنها مانند همان روش تصادفی (استفاده از t-test، رگرسیون و…)
- نشان دهیم که تفاوتها اثری بر شاخص نتیجه ندارند (با استفاده از دادههای تاریخی و مطالعات دیگر)
در روش اول، از مدل رگرسیون (Multiple Regression) استفاده میشود که سهم (درصد) تأثیرات همه فاکتورهای مربوط (که هم شامل مداخله و هم سایر فاکتورهای مؤثر است) را بهصورت جداگانه تخمین میزند (بر اساس پارامتر R). البته این مدلها یک فرضی دارند و آن اینکه رابطه میان متغیرها، شکل خاصی دارد (خطی، سهمی و…).
در روش دوم، مشکل فوق وجود ندارد، ولی قسمت قابل توجهی از دادهها، کنار گذاشته میشود. همچنین اجرای روش دوم، پیچیدهتر است. برای اینکه از match بودن (همسان بودن) دو گروه بیشتر مطمئن شویم، خوب است توابع توزیع آنها مقایسه شوند. این کار حتی در شرایط «آزمایش کامل» نیز توصیه میشود، مخصوصاً در مواقعی که اندازه نمونه کوچک است (چون ممکن است نمونهگیری متوازنی انجام نگرفته باشد).
دو نمونه از روش PSM
۱- همسانسازی گروهها؛ کاربردی از تکنیک PSM در سیاست کار و بازنشستگی [۱۵]
در سال ۲۰۰۰ برنامهای از طرف وزارت کار و بازنشستگی انگلستان برای زنان (یا مردان مجردِ) سرپرست خانوار[۱۱] (NDLP) که از حمایتهای درآمدی دولت[۱۲] (IS) بهره میگرفتند، اجرا شد. هدف در این برنامه کمک به این افراد برای ورود به بازار کار و خروج آنها از این برنامههای حمایتی بود.
ارزیابیهای قوی برای این برنامه در نظر گرفته شده بود که یکی از عناصر آن، اندازهگیری میزان اختلاف[۱۳] در برنامه بود (به معنی فواید حاصله از اجرای برنامه). به هر حال، چالشهایی در رسیدن به این هدف وجود داشت که از این قرار بودند:
- مقایسه مکانی گروهها ممکن نبود چرا که برنامه در کل مناطق انگلستان اجرا میشد.
- همه اعضای گروه هدف برنامه به پیوستن به برنامه دعوت و در آن وارد شده بودند، بنابراین فرصتی برای انتخاب یک گروه مقایسه از افرادی که تحت مداخله قرار نگرفته بودند، وجود نداشت.
روش همسانسازی PSM برای این برنامه انتخاب شد، به این علت که اجازه میداد تا نمونه مقایسهای از افرادی که در برنامه حضور نداشتند، تشکیل شود. بنابراین با اجرای این روش، گروه تحت مداخله و گروه مقایسه بر اساس امتیاز تمایل[۱۴] دستهبندی شدند. این امتیاز بر اساس احتمال شرکت در برنامه بسته به تمامی عوامل مؤثر (هم بر شرکت در برنامه و هم بر نتایج)، محاسبه شد. یکی از عواملی که دادههای مستقیمی از آن جمعآوری شد، انگیزه/نگرش برای شرکت در برنامه بود.
یک نمونه طبقهبندی شده در حدود ۷۰هزار نفر از زنان (مردان مجرد) سرپرست خانوار در بازه زمانی ۲ماهه در سال ۲۰۰۰ انتخاب شدند. سپس این نمونه، به دو گروهِ افراد شرکتکننده در برنامه و افرادی که در برنامه شرکت نمیکنند، تقسیم شد. سپس با اجرای تکنیک PSM، گروه افراد شرکتکننده با یک نمونه مقایسه از افرادی که در برنامه شرکت نمیکنند، match شدند؛ برای محاسبه امتیازات، از بانکهای اطلاعاتی موجود و دادههای پیمایشی (از جمله عامل نگرش) استفاده شد.
نتایج مطالعات نشان از تأثیر مثبت برنامه NDLP بر ورود به بازار کار داشت. بعد از ۶ ماه، درمقایسه با ۱۹ درصد افراد گروه مقایسه که وارد بازار کار شدند، ۴۳ درصد افراد تحت مداخله به شغلهای تماموقت یا پارهوقت اشتغال پیدا کردند. بنابراین ۲۴ درصد افزایش بر اثر اجرای برنامه بهوجود آمده بود. نتایج مشابهی در نرخ خروج از تسهیلات دولتی انگلستان بعد از اجرای برنامه مشاهده شد که مؤید دیگری بر مثبت بودن برنامه NDLP بود.
۲- کابرد تکنیک PSM در برنامه آموزش و اشتغال [۲۷]
برنامه آموزش و مهارتهای اشتغال شهرستان کینگ[۱۶] (EET) از یادداشت تحلیل را به خاطر آورید. این برنامه با هدف کمک به بهبود وضعیت نوجوانان در معرض خطر شهرستان کینگ ایالت واشنگتن اجرا میشود و مؤسسه WSIPP که پیشتر درخصوص ساختار و ویژگیهای آن صحبت کردیم، ارزیابی این برنامه را به عهده گرفته است. در سندی که WSIPP با هدف ارزیابی نتایج و تحلیل هزینهفایده برنامه EET منتشر کرده است، به جزئیات محاسبه شاخصها و همچنین روند تحلیل هزینه-فایده برنامه اشاره شده است. در ادامه با مراجعه به این سند، به بررسی سازوکار ارزیابی این برنامه خواهیم پرداخت.
یکی از مهمترین خروجیهایی که در این برنامه مورد انتظار است، کاهش نرخ تکرار جرم[۱۷] است. تخمین تأثیر EET بر تکرار جرم، نیازمند مقایسه گروه مورد مداخله (treated group) با گروهی دیگر که واجد شرایط برای مداخله بودند اما مورد مداخله قرار نگرفتهاند (comparison group)، میباشد. در حالت ایدهآل، این ارزیابی تأثیر با استفاده از طراحی یک آزمایش کامل که در آن افراد واجد شرایط برنامه به صورت تصادفی به یکی از گروههای مورد مداخله یا گروه مقایسه تخصیص مییابند، انجام میشود و بنابراین تفاوتها در نتایج بعدی، با اطمینان بالا مربوط به تأثیرات برنامه EET میباشد. برای طراحی بهتر آزمایش و همسان کردن دو گروه آزمایش، از تکنیک PSM استفاده شده است که در ادامه، درباره نحوه تخصیص افراد به گروهها توضیح میدهیم.
گروه تحت مداخله (treated group) شامل افرادی است که بین بازه زمانی ۱ ژانویه ۲۰۱۱ تا ۳۱ دسامبر ۲۰۱۲ وارد برنامه شدهاند. این افراد، از نوجوانان شهرستان کینگ هستند (که تنها جایی است که دادگاه آن به اجرای این برنامه میپردازد). گروه مقایسه (comparison group) نیز شامل نوجوانانی است که ریسک ارتکاب جرم متوسط به بالایی دارند و در همین بازه زمانی، واجد شرایط برخورداری از برنامه میباشند[۱۸] و ساکن شهرستانهای پیرس و اسنومیش هستند. پیش از match کردن، ۲۷۲ نوجوان در گروه تحت مداخله و ۶۲۸ نوجوان در گروه مقایسه بودند.
اجرای تکنیک PSM در این برنامه، سه گام داشت: ابتدا امتیاز تمایل (احتمال اینکه یک نوجوان با توجه به ویژگیهای جمعیتی، جنایی و رفتاری، در برنامه EET مورد مداخله قرار بگیرد) برای افراد هر دو گروه تحت مداخله و مقایسه، تخمین زده میشود. برای این تخمین، از یک مدل آماری استفاده میشود که متغیرهای فوق (جمعیتی، جنایی و رفتاری) به عنوان متغیرهای کنترلی در نظر گرفته میشوند.
در گام دوم، افراد هر دو گروه بر اساس امتیاز تمایل مرتب شده و هر فرد از گروه مقایسه به نزدیکترین فرد از گروه تحت مداخله (بر اساس امتیاز تمایل)، match میشود. بعد از این کار، ۲۶۶ نوجوان در گروه تحت مداخله و ۲۶۶ نوجوان در گروه مقایسه قرار گرفتند.
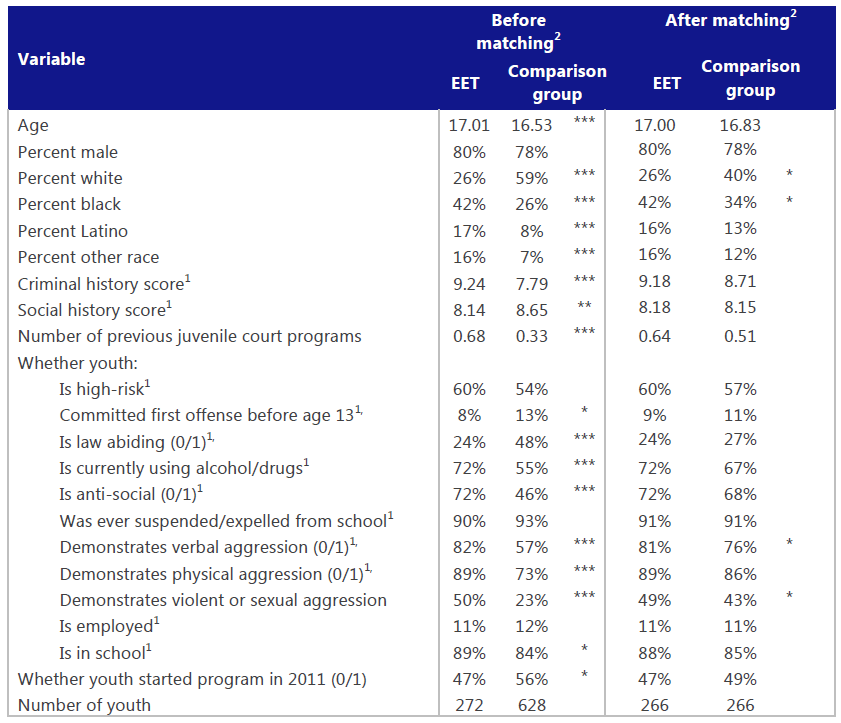
در جدول زیر مشخصات افرادی که بر اساس متغیرهای مختلف معرفی شده، (پیش و پس از match کردن) در گروههای تحت مداخله یا مقایسه قرار گرفتهاند، آورده شده است؛ مشاهده میشود که این دو گروه در مشخصات اصلی خود، بسیار به هم شبیه شدهاند:
در گام سوم، با استفاده از روشهای آماری آزمایش کامل، میتوان تأثیر برنامه EET را (در شاخصی مانند میزان احتمال تکرار ارتکاب جرم) محاسبه نمود. در این تخمین، برای بالابردن دقت، متغیرهای جمعیتی، رفتاری و جنایی نیز به صورت متغیرهای کنترلی در نظر گرفته شده و از یک مدل رگرسیون لگاریتمی برای این تخمین استفاده میشود.[۱۹]
همانطور که در نمودار زیر مشخص است، افراد تحت مداخلهی EET نسبت به افرادی که در EET نبودند، از احتمال «تکرار ارتکاب جرم» کمتری برخوردار شدند و بدین ترتیب تأثیر مثبت اجرای برنامه EET بر تکرار ارتکاب جرم نشان داده شد.
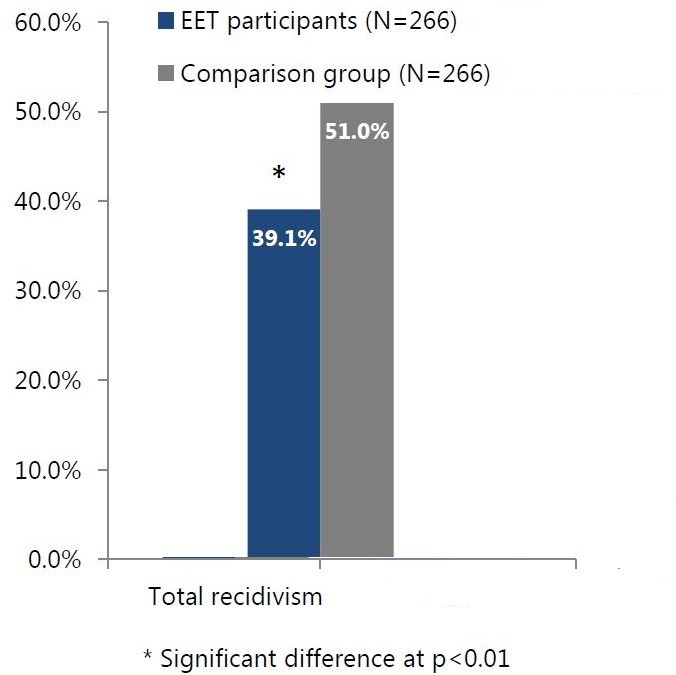
البته فرض روشهای فوق این است که ما همه فاکتورهای مؤثر بر نتایج را شناسایی و مشاهده کردهایم. در غیر این صورت، نمیتوان اثر خالص مداخله را شناسایی کرد. یک روش دیگر که این ضعف را ندارد (یعنی دیگر لازم نیست حتماً همه فاکتورهای مؤثر را بشناسیم)، روش[۲۰] DiD است. در این روش، تغییر روند نتایج گروههای مورد مداخله و مقایسه، در یک بازه زمانی (که مداخله در آن بازه صورت گرفته)، مقایسه میشوند. در این روش فرض میشود که سایر فاکتورها، شاید بر نتایج اثر بگذارند، ولی بر تغییر روند آنها اثری ندارند. لذا روند دو گروه در غیاب مداخله یکسان خواهد بود و هر تفاوت قابل توجه در روند گروهها، اثر سیاست دانسته میشود[۲۱]. لذا اثر سیاست را میتوان با بررسی روندهای پیش از مداخله در سریهای زمانی تاریخی یا مطالعات قبلی و مقایسه آن با روند پس از مداخله چک کرد. به همین دلیل در جایی که فقط دو داده از شاخص نتیجهای داریم (مربوط به قبل و بعد از اجرای سیاست)، استفاده از این روش توصیه نمیشود. هر چه دادههای تاریخی بیشتری را بررسی کنیم، با اطمینان بیشتری میتوانیم بگوییم که تغییر روند، ناشی از مداخله ما بوده است یا خیر.
نمونهای از ارزیابی به روش DiD؛ ارزیابی چندوجهی برنامهای در حوزه بهداشت محل کار
برنامه (خدمت) «سلامت محل کار»[۲۲] (WHC) به طور آزمایشی در بازه زمانی ۲۰۰۶ تا ۲۰۰۸ در انگلستان به اجرا درآمد. این خدمت به طور رایگان و داوطلبانه و برای شرکتهای کوچک و متوسط مقیاس (SMEs) ارائه میشد و به واسطه آن توصیههایی به شرکتهای انگلیسی برای افزایش سطح سلامت محیط کار داده میشد.
در ارتباط با این خدمت، مطالعهای به منظور ارزیابی آن با اهداف زیر صورت گرفت:
- آیا این خدمت، تأثیر روشنی بر میزان آسیبهای وقوع یافته در محل کار و در زمان اشتغال به کار، داشته است؟
- هزینهها، فواید و موانع مرتبط با اجرای این برنامه چه بوده است؟
رویکردی روش شناختی برای رسیدن به این اهداف اتخاذ شد که در آن پیمایشهایی به منظور جمعآوری دادهها صورت گرفت. دادههای جمعآوری شده با در نظر گرفتن مواردی بود که عبارتند از: تجربیات منطقهای از ارائه خدمت، ایجاد یک گروه مقایسه و جمعآوری دادههای آن، مطالعههای موردی و تعیین هزینههای اجرای WHC در شرکتهایی که آن را ارائه کردند.
گروه مقایسه این روش از بین سازمانهایی انتخاب شد که خدمت WHC در آنجا ارائه نمیشد و از نظر اندازه و صنعت، با نمونه پایلوت مشابه بودند. دادههای پیمایش شامل ۵۲۰ سازمان بود که در گروه تحت مداخله قرار میگرفتند. ۱۶۰۹ سازمان نیز در گروه مقایسه دستهبندی شدند. هر سازمان دو بار تحت مصاحبه قرار گرفت که بین این دو مصاحبه فاصله زمانی یکساله قرار داشت. علت این فاصله زمانی هم تغییر در نتایج سلامت و ایمنی سازمانها در این بازه بود.
یک راه برای ارزیابی اجرای آزمایشی WHC توجه مستقیم به ارتباط بین مشارکت در برنامه آزمایشی و نتایج نهایی بود. این رویکرد به هر حال باعث ایجاد نتایج قوی و قابل اتکایی نشد (زیرا اجرای پایلوت، نه تنها بر بهبود ایمنی، بلکه بر نحوه ثبت نتایج نهایی هم اثرگذار بود). به همین دلیل رویکرد دیگری اتخاذ شد مبتنی بر تحلیل ارتباط بین دو مرحله، ابتدا توجه به تأثیر اجرای آزمایشی WHC بر نتایج واسطهای و سپس بررسی تأثیر نتایج واسطهای بر نتایج نهایی اجرای برنامه. این ارتباط با استفاده از روش DiD مورد بررسی قرار گرفت. اجرای روش به این صورت بود که تغییر در نتایج در فاصله زمانی دو بار مصاحبه ثبت شد و بررسی شد که آیا این تغییرات، در گروه مقایسه و تحت مداخله متفاوت هستند یا خیر[۲۳].
علاوه بر دادههایی که به صورت مستقیم در مطالعه استفاده میشد، در طی مصاحبهها، اطلاعاتی مربوط به ویژگیهای عمومی شرکتها نیز جمعآوری شدند تا در تقسیم گروهها به تحت مداخله و مقایسه و نهایتاً نزدیککردن فاکتورهای دو گروه به یکدیگر به کار بیایند.
ارزیابیهای این خدمت نهایتاً نشان از نتایج و تأثیرات مثبت اجرای آن بر شرکتها، داشت و نتایج نشان میداد مشارکت در این برنامه منجر به بهبود برخی ملاحظات بهداشتی و ایمنی در محیط کار شده و متعاقب آن نرخ حوادث در محیط کار کاهش یافته است. همچنین هزینههای خدمت در محلهای مورد ارائه نیز در ارزیابیها محاسبه و نتایج آن حاکی از ایجاد درآمدهایی برای مشارکتکنندگان بود.[۲۴]
در شرایطی که امکان در اختیار داشتن گروه مقایسه فراهم نباشد (به خاطر اینکه مداخله همه جا همزمان برگزار شده یا اینکه دادهای برای افرادِ کنارگذاشتهشده (بدون مداخله) نداشته باشیم)، میتوان از پیشبینی یا برونیابیِ نتایج با استفاده از دادههای تاریخی، یک گروه مقایسه فرضی درست کرد. به این روش، طراحی سریهای زمانی منقطع[۲۵] گفته میشود. این روش در شرایطی قابل استفاده است که اولاً عوامل اثرگذار شناخته شده باشند و ثانیاً میزان اثر به اندازه کافی بزرگ باشد که خطای پیشبینی در برابر آن قابل اغماض باشد. در کل استفاده از این روش، جز در موارد معدود توصیه نمیشود. روش دیگر، استفاده از دادههای مربوط به شاخصهای نتیجهای مشابه است که پیش از این، روندی موازی شاخص نتیجهای مداخله مدنظر داشته است. مثلاً یک جرم مشابه یا یک بیماری مشابه.
اما آنچه در این قسمت گفته شد، روشهای ارزیابی تأثیر برای شاخصهای سطح فردی است. همانطور که از در یادداشتهای بعد (مباحث ساختاری) خواهید دید، گاه یک مداخله سیاستی، سطوحی بالاتر از سطح فردی را هدف قرار میدهد؛ در این حالت، شاخصهای نتیجهای، از جنس متغیرهای سطوح بالاتر است؛ مثلاً فرض کنید در یک سیاست آموزشی، علاوه بر دادههای مربوط به دانشآموزان، اینکه آنها در چه مدرسهای مشغول به تحصیل هستند هم مشخص باشد. در این شرایط، معمولاً از رویکرد مدلسازی چندسطحی[۲۶] (MLM) استفاده و تأثیر سیاست بر هر دو نوع متغیر سطح فردی و گروهی (کل مدرسه) سنجش میشود. علاوه بر این، گاهی شاخص نتیجهای مدنظر، فقط در سطح بالاتر از فرد معنادار است. در این مورد، نیازی به رویکرد چندسطحی نداریم و دقیقاً مانند ارزیابیهای سطح فردی عمل میکنیم. البته از نظر قابلیت اطمینان آماری و توان، تفاوتهایی با آن وجود دارد که استفاده از این متغیرها را بسیار محدود میکند: عدم امکان داشتن نمونههای بزرگ و تنوع بیشتر میان واحدها (و در نتیجه سختتر شدن تشکیل گروه مقایسه همسان).
آنچه در این قسمت گفته شد، در شرایطی است که سیاست از ابتدا طوری طراحی شده که گروه مقایسه در نظر گرفته شود. اما گاهی این طور نیست: یا اینکه جداسازی دو گروه و تخصیص سیاست صرفاً به گروه خاص ممکن نیست، یا اینکه دادههای باکیفیت در دسترس نیست، یا اینکه سیاست قبلاً اجرا شده و درون آن، مسائل مربوط به تحقیق و ارزیابی در نظر گرفته نشده بوده است. در این شرایط، چند کار میتوان انجام داد:
- گاه بدون اینکه عمدی در کار بوده باشد (مثلاً به خاطر یک عامل خاص)، یک «آزمایش طبیعی» رخ داده و بهطور اتفاقی، یک گروه مقایسه ایجاد شده (گروهی با مشخصات مشابه که تحت تأثیر سیاست قرار نگرفتهاند).
- گاهی اوقات برخی شاخصهای نتیجهای صرفاً قبل و بعد از اجرای مداخله سنجش شده و دادههای مقایسه موجود نیست. این دادهها تنها زمانی واقعاً معتبر هستند که سیستم مورد مطالعه آنقدر ساده باشد که مداخله ما تنها چیزی باشد که بهطور منطقی انتظار میرود بر نتایج مؤثر باشد (باید یک قضاوت محکم برای این موجود باشد و نه صرفاً نبود توضیح دیگر). متأسفانه سیستمهای اجتماعی، کمتر اینقدر ساده هستند و در این صورت نباید این دادهها به عنوان ارزیابی تأثیر قلمداد شوند.
- استفاده از اطلاعات ارزیابی فرایند؛ با اینکه مطالعات فرایندی، امکان ارزیابی کمّی تأثیرات را به ما نمیدهد، اما آنها میتوانند راجع به جهت تغییرات به ما بینش دهند. مثلاً آیا کارکنان عملیاتی حاضر در اجرای مداخله، احساس خوبی راجع به این دارند که مداخله اثربخش بوده و چرا؟
آیا شما در مورد مطالب این یادداشت، تجربه سیاستی دیگری (در داخل یا خارج از کشور) را سراغ دارید؟ درصورت تمایل، این تجربهها را در قسمت دیدگاه با ما در میان بگذارید تا با نام خودتان منتشر شود.
[*] مطالب این یادداشت برگرفته از سند زیر هستند:
HM Threasury. (2011). The Magenta Book Guidance for evaluation. London: HM Threasury.
[۱] association
[۲] experiment یا Randomised Controlled Trial -RCT
[۳] the Enhanced Thinking Skills
[۴] Impulsivity: افرادی که با انگیزه آنی و بدون فکر قبلی عمل میکنند.
[۵] این نمونه موردی برگرفته از سند زیر است:
HM Threasury. (2011). The Magenta Book Guidance for evaluation. London: HM Threasury, p. 108.
[۶] threshold
[۷] به این روش، RDD- regression discontinuity design- گفته میشود.
[۸] strength
[۹] Power
[۱۰] propensity score matching
[۱۱] New Deal for Lone Parents -NDLP
[۱۲] Income Support
[۱۳] counterfactual
[۱۴] propensity score
[۱۵] این نمونه موردی برگرفته از سند زیر است:
HM Threasury. (2011). The Magenta Book Guidance for evaluation. London: HM Threasury, p. 116.
[۱۶] The King County Education and Employment Training -EET
[۱۷] recidivism rates
[۱۸] واجد شرایط بودن یعنی نوجوانانی که با حداقل سن ۱۵ سال، ریسک ارتکاب جرم متوسط به بالایی دارند و نیز سایر شرایط EET را دارند.
[۱۹] در بخش ضمیمه سند ارزیابی مذکور، در خصوص این تکنیک و چگونگی پیادهسازی آن، توضیحات مفصلتری داده شده است.
[۲۰] difference in difference یا two group pre- and post-test design
[۲۱] تفاوت اصلی کار در اینجا نسبت به روش رگرسیون این است که برای هر یک از اعضای نمونه، باید در طول زمان (حداقل یکی قبل و یکی بعد از مداخله) داده جمعآوری شود و تغییرات آن سنجیده شود. در عوض برای متغیرهای کنترلی، داده جمعآوری نمیکنیم.
[۲۲] Workplace Health Connect -WHC
[۲۳] در واقع برای هر شاخص نتیجهای، برای هر یک از گروههای مداخله و کنترل، یک بار قبل از مداخله و یک بار بعد از مداخله (pre-test, post-test) داده جمعآوری شده است.
[۲۴] این نمونه موردی برگرفته از سند زیر است:
HM Threasury. (2011). The Magenta Book Guidance for evaluation. London: HM Threasury, p. 117.
[۲۵] interrupted time series -ITS
[۲۶] multi-level modelling
[۲۷] برگرفته از سند زیر:
http://www.wsipp.wa.gov/ReportFile/1621/Wsipp_The-King-County-Education-and-Employment-Training-EET-Program-Outcome-Evaluation-and-Benefit-Cost-Analysis_Report.pdf